


相关实验
实验承诺函
咨询记录
技术文章





城市
时间
辽宁省沈阳市
2025-12-13 18:42:25
湖南省长沙市
2025-12-13 18:38:13
湖南省长沙市
2025-12-13 18:36:41
广东省东莞市
2025-12-13 14:15:11
陕西省西安市
2025-12-13 13:16:38
辽宁省沈阳市
2025-12-13 10:52:27
辽宁省沈阳市
2025-12-13 04:43:41
江苏省苏州市
2025-12-13 02:15:07
浙江省湖州市
2025-12-12 21:17:39
福建省厦门市
2025-12-12 21:10:27
高中阶段我们学过中心法则,中心法则是指遗传信息从DNA传递给RNA,再从RNA传递给蛋白质,即完成遗传信息的传递过程。生物体的绝大部分生命活动都遵循该法则。中心法则主要是围绕DNA,RNA,蛋白质来展开,通过这个过程实现遗传信息的表达与传递。
那三个生物大分子之间是如果进行遗传信息的传递的呢?首先,遗传信息储存在DNA中,通过转录将遗传信息转移到mRNA中,mRNA中含有密码子,一个密码子决定一个氨基酸,氨基酸最终组成蛋 白质,这个过程也就是蛋白质的翻译过程。除了mRNA 以外,RNA还包括rRNA(它与蛋白质结合而形成核糖体,其功能是在mRNA的指导下将氨基酸合成为肽链),tRNA(tRNA能根据mRNA的遗传密码依次准确地将它携带的氨基酸连结起来形成多肽链)。
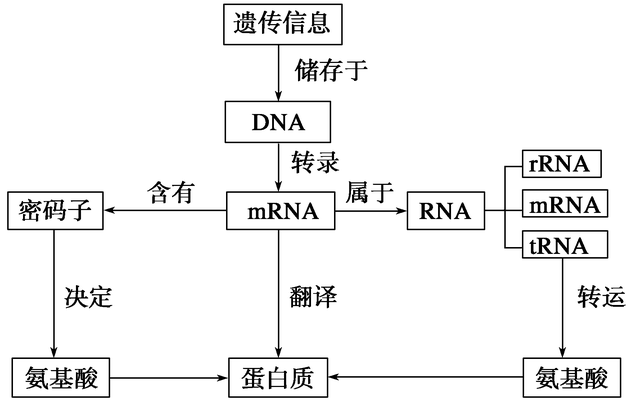
图一 中心法则
转录翻译过程及元件介绍 )
Part2
今天我们以前来回顾一下真核生物基因表达的过程,这个过程涉及许多的名词,在平时的科研生活中,很多同学对这些名词也都很困惑,今天咱们就系统性的来复盘一下。
首先我们看一下基因的结构:基因是染色体上具有控制生物性状的DNA片段。基因在结构上可分为编码区和非编码区,且非编码区多于编码区。在非编码区,存在着许多的元件,它们虽不直接参与基因的转录和翻译,但也对基因的表达起这重要的作用。
↓↓↓在这里
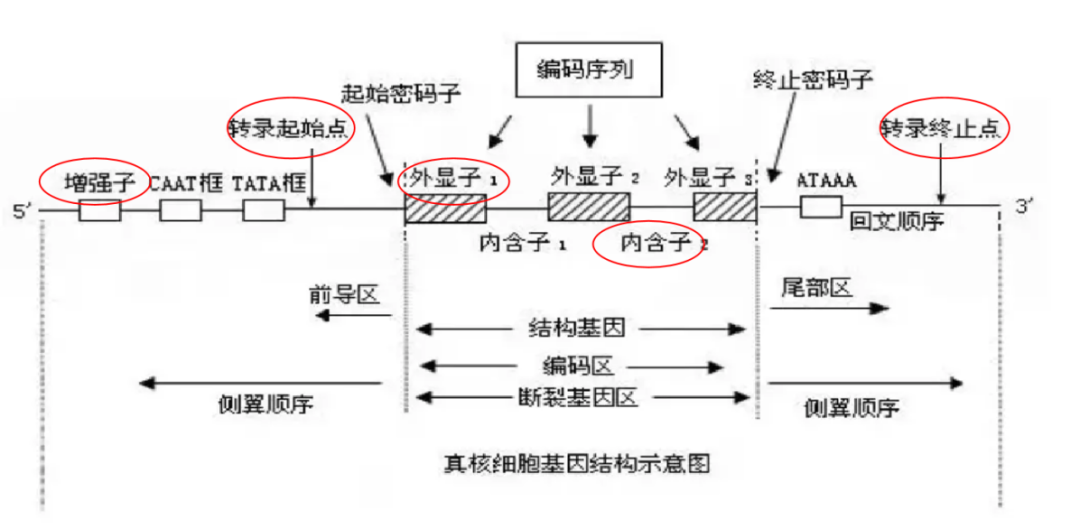
图二 基因结构及作用元件
增强子是存在于DNA上的一段可以与蛋白质结合的区段,增强子通过影响DNA的结构和功能,结合特定的转录因子和辅因子,从而激活或增强基因的转录,对真核基因的时空表达起着重要的调控作用。
启动子的主要作用是启动和调控基因的转录。启动子可以活化RNA聚合酶,使之与模板DNA准确地结合并具有转录起始的特性。它能够指导全酶同模板正确结合,活化RNA聚合酶,启动基因转录。启动子区一般包含两个保守结构域,分别是CAAT Box(控制转录起始的频率)和TATA Box(使转录精确地起始)。
终止子是位于基因末端,给RNA聚合酶提供转录终止信号的DNA序列。
沉默子:沉默子是一段能够结合转录调节因子的DNA序列,这种转录因子称为阻遏蛋白。与增强子对DNA转录的加强作用相反,沉默子会抑制DNA的转录过程。
非编码区的这些元件统称为顺式作用元件包括启动子,增强子,沉默子等,可与转录因子结合。
说完了非编码区,我们再来看看编码区。编码区主要由内含子和外显子组成,真核生物绝大部分是断裂基因,内含子和外显子交替排布。
外显子是断裂基因中的编码序列,在后续mRNA的加工过程中被保存,是能编码蛋白质的核苷酸序列。
内含子是基因中无编码功能的序列,也存在于pre-RNA中。
那么基因又是怎么成为直接参与生物体生命活动的蛋白质的呢?这就涉及到基因的表达,今天我们主要讲一下基因表达的转录和翻译这两个过程。
转录:是以DNA为模板,以4种NTP为原料,依据碱基配对规律,在DNA 指导(或依赖 DNA)的 RNA聚合酶催化下合成RNA的过程。真核生物的转录涉及许多的酶类以及蛋白因子,其中最重要的是转录因子和RNA聚合酶。
转录因子(Transcription Factors, TFs)指能够以序列特异性方式结合DNA并且调节转录的蛋白质。包括TFIIA、TFIIB、TFIID、TFIIE、TFIIF、TFIIH、TFIIJ。
RNA聚合酶(RNA polymerase)是以一条DNA链或RNA为模板,三磷酸核糖核苷为底物,通过磷酸二酯键而聚合的合成RNA的酶,包括RNA聚合酶Ⅰ(合成rRNA),RNA聚合酶Ⅱ(合成mRNA),RNA聚合酶Ⅲ(合成tRNA),线粒体RNA聚合酶(合成线粒体RNA)。
了解完转录的基本概念和所需的重要的蛋白质和酶类后我们来看看转录的具体过程,转录分为3个过程,分别为转录起始,转录延长,转录终止。
起始:RNA聚合酶对转录起始位点上游的DNA序列进行辨认,同时打开DNA双螺旋结构,依赖转录因子结合启动子形成复合物。
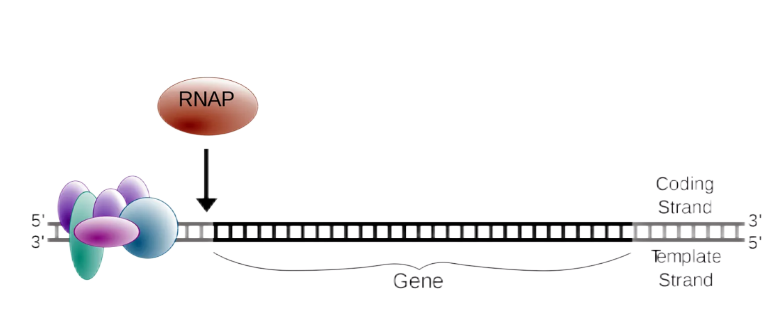
图三 转录起始
延长:合成一段含有60-70个核苷酸的RNA分子后,RNA聚合酶根据碱基互补配对原则,从5’-3’方向逐个加入核糖核苷酸,进入转录延长期。
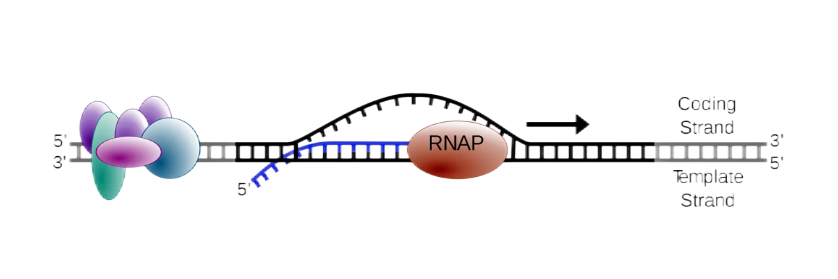
图四 转录延长
终止:真核生物目前并没有明确的转录终止信号,且3种RNA的合成终止方式不同。对于mRNA来说,在结构基因的最后一个外显子的3’端常有一组共有序列AATAAAA,其下游还有GT序列,这些序列为转录终止的修饰点,当RNA聚合酶转录出AAUAAA后,多聚腺苷酸特异因子(CPSF)能识别并与它结合,指导前mRNA的切割。在CPSF及切割活化因子(CstF)等因子的指导下,特异的内切核酸酶在AAUAAA下游11-30个核苷酸出切断RNA链, mRNA前体转录停止。

图五 转录终止
刚转录出来的mRNA又被称为核不均一RNA(hnRNA),该RNA分子量非常大,且仅有10%的部分后期能转变成成熟的RNA,其余部分在转录后的加工过程中被降解。其结构为:转录起始位点、外显子、内含子、转录终止位点。
hnRNA又是如何成为成熟的mRNA的呢?这就涉及到mRNA前体物质的加工过程,真核生物mRNA的加工一般包括:mRNA前体剪接,mRNA的修饰(5’加帽和3’多聚腺苷酸化),mRNA编辑。
5’帽子结构:合成一段RNA后,在链5’端加入鸟嘌呤核苷酸且在鸟嘌呤7号位氮上发生甲基化形成一个类似于帽子的结构。帽子结构的生理功能主要是为核糖体识别mRNA提供了信号,帽子结构是核糖体识别mRNA所必须的;帽子结构增加mRNA的稳定性,保护mRNA免受5’外切核酸酶的降解;帽子结构还能有助于成熟的mRNA的转运,有助于前体RNA的正确拼接。
3’多聚腺苷酸尾巴:与hnRNA的形成同步发生。先由核酸外切酶切去前体RNA的一些核苷酸,再加入polyA尾。多聚腺苷尾巴结构的生理功能主要是提高RNA的稳定性;增强RNA的翻译效率。
mRNA前体剪接:内含子区段弯曲使外显子靠近,然后在5’-GU/AG-3’处经过两次转脂反应被剪去后外显子进行拼接。外显子不同的拼接方式会导致不同的转录本(转录本是由一条基因通过转录形成的一种或多种可供编码蛋白质的成熟的mRNA)的产生,这里就涉及到不同的转录本问题(对转录本有研究的小可爱评论区留言,讨论)。
mRNA 编辑:对外显子进行加工,核苷酸的插入、删除或转换,从而改变RNA的序列使遗传信息在mRNA上发生改变。
经过加过后前体RNA成为去掉内含子,加上帽子结构(GpppmG),加上polyA尾巴的成熟的可被翻译成蛋白质的mRNA。加工过程如下图。
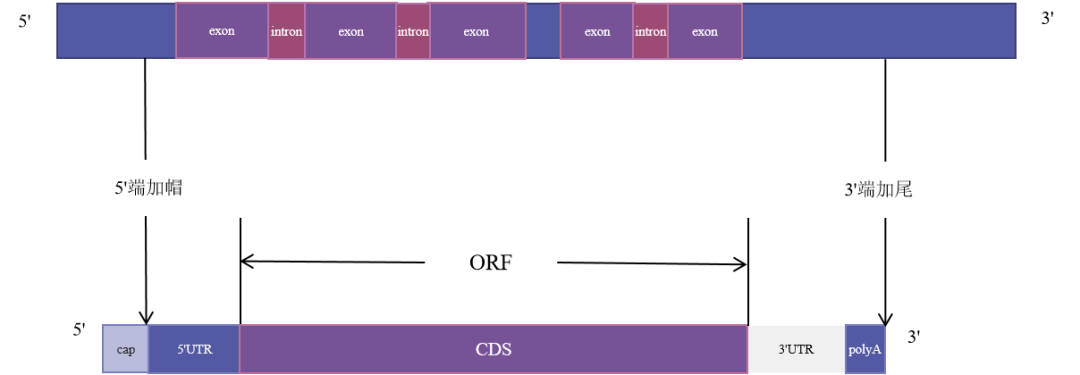
图六 前体RNA的加工成熟过程
其结构包括:5’帽子结构、5’UTR区、CDS区、3’UTR区、polyA尾巴。那各个区段的含义又是如何,接下来我们一个个来解释。
5’UTR: 5’UTR区位于帽子结构之后,指从mRNA的一端到编码序列的起始密码子之间的一段序列。该区域可能包起始始密码子序列、RNA稳定性元件和翻译起始调控序列。5’UTR是翻译起始的高度敏感区,其长度、二级结构以及AUG的数量都会影响翻译起始的效率。
编码区(CDS):编码区包括mRNA的一系列密码子,它们会被翻译成蛋白质的氨基酸序列。编码区由起始密码子(通常为AUG)和终止密码子(例如UAA、UAG或UGA)标识。生物学中构建的各种载体时所需的引物都是针对CDS来设计合成的。需要与ORF区分开来(开放阅读框是从起始密码子到种子密码子中间的序列。CDS必定是一个ORF。但也可能包括很多ORF。反之,每个ORF不一定都是CDS)。
3’UTR: 3’UTR区指从编码序列的终止密码子到mRNA链的末端之间的一段序列。该区域可能包含稳定性元件、调控序列和终止子序列。
接下来根据成熟信使RNA的核苷酸顺序,以3个核苷酸组成一个遗传密码决定一个氨基酸的方式合成多肽,从而将mRNA中的遗传信息转换成蛋白质氨基酸序列。翻译过程同样涉及许多重要的酶、蛋白因子等。
核糖体(Ribosome)是翻译发生的场所,是翻译过程中mRNA结合tRNA的空穴,有A位(氨酰tRNA进入核糖体后占据的位置)和P位(肽酰tRNA进入核糖体后占据的位置),核糖体包括大小两个亚基。
遗传密码(condon)是指mRNA分子上沿5'端到3'端方向,由起始密码子AUG开始,每三个核苷酸组成的三联体。它决定肽链上每一个氨基酸和各氨基酸的合成顺序,以及蛋白质合成的起始、延伸和终止,遗传密码子分为起始密码子(AUG)和终止密码子(UAG、UAA、UGA)。
tRNA称为转运RNA,既能识别mRNA上的遗传密码,又能与相应的氨基酸结合。tRNA上含有反密码子,可与密码子配对,确保氨基酸的准确性。在翻译过程中tRNA可以跟氨基酸结合成为氨酰-tRNA(位于核糖体的A位点上),也可以跟肽链结合成为肽酰-tRNA(位于核糖体的P位点上)。
翻译过程中也需要许多的因子来协助,包括起始因子(参与蛋白质起始复合物的形成),延长因子(与氨酰-tRNA及GTP结合形成复合物,将氨酰-tRNA转入A位点)和释放因子(识别终止密码子,终止肽链的合成释放肽链)。
我们来了解下翻译的基本过程。翻译的基本过程也分为三个:翻译起始、翻译延长、翻译终止。
翻译起始:翻译过程主要的事件是起始氨酰-tRNA和mRNA分别与核蛋白体结合形成翻译起始复合物。主要分为以下几个步骤,首先核糖体大小亚基分离,核糖体40S小亚基与起始tRNA结合甲硫氨酸形成起始复合物前体;同时由于转录起始复合物前体与AUG距离较远,因此需要沿着mRNA链进行扫描,直至第一个AUG与tRNA的反密码子配对,mRNA才准确定位在核糖体小亚基;核糖体大亚基结合;当起始复合物前体识别AUG后,核糖体小亚基在酶的作用下解离,核糖体大亚基结合,形成翻译起始复合物。
翻译延长:主要事件是翻译起始复合物形成后,核糖体从mRNA的5’端向3端移动,依据密码子顺序,从N端开始向C端合成多肽链。通常分为3个过程:进位(核糖体A位点上mRNA密码子所规定的氨酰-tRNA进入核糖体A位点);转肽(氨酰-tRNA进位后,核糖体A位和P位上各结合了一个氨酰-tRNA,在酶的催化下,P位上的起始tRNA所携带的甲酰甲硫氨酰基的羧基与A位点的氨基酸的ɑ氨基形成肽键);移位(在延长因子的催化下,GTP水解为移位提供能量,使mRNA与核糖体相对移位一个密码子的距离,P位上的tRNA从P位释放,A位上的肽酰-tRNA移到P位,mRNA分子上的第三个密码子进到A位,为下一个氨酰-tRNA进位做好准备)。
翻译终止:当mRNA上出现终止密码子后,氨酰-tRNA无法结合到A位,但释放位子可以进入A位,此时核糖体上的肽链脱落,mRNA与核糖体分离,核糖体解离成大小亚基。
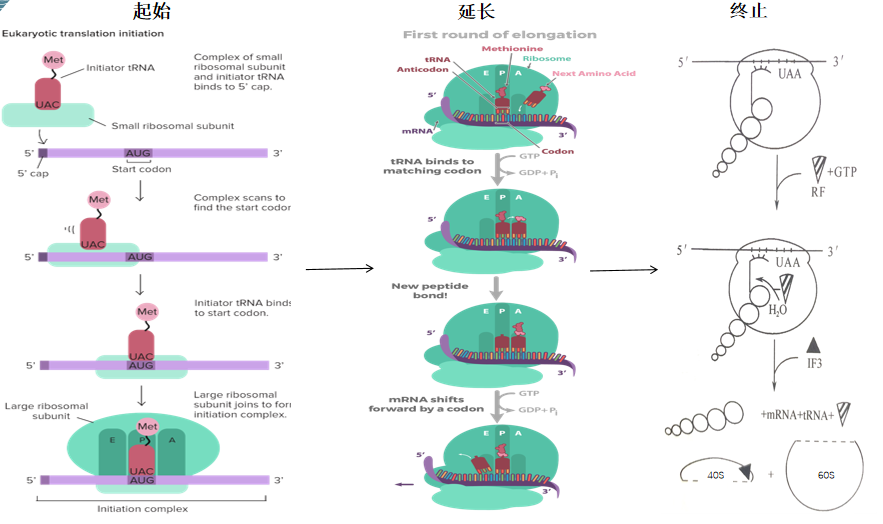
图七 真核生物翻译过程
至此,一个具有特定生物学功能的蛋白质合成完成。
( 各元件序列下载 )
Part3
转录和翻译过程中涉及了非常多的元件,各自的序列也有不同的特点,那我们日常使用的比较多的序列主要是以下几种,我们先来了解一下这些序列平时的用途。
启动子序列:转录因子预测;启动子序列对比及保守性分析。
CDS序列:不论是PCR还是QPCR,都是根据CDS序列来设计引物进行扩增以便进行后续的实验。
UTR区:对于研究一个基因的不同的剪切本有帮助(5’UTR区含有内含子,内含子最突出的作用是可以被选择性剪接,进而产生不同功能的蛋白质,并且无论内含子处于在基因结构的哪个位置,均可以调控基因的表达并涉及到每一步,包括mRNA的转录、翻译、定位以及衰变等过程)。miRNA和靶基因的相互作用关系(双荧光素酶实验)。
蛋白质序列:我们可以将获取的氨基酸序列用特定发的蛋白质分析软件进行分析,以便我们可以了解蛋白质基本性质分析;疏水性分析;跨膜区预测;信号肽预测;亚细胞定位预测;抗原性位点预测(相关网站如下:SCOP蛋白质结构分类数据库;PDB数据库;UniProt数据库;SWISS-PROT 数据库;Pfam数据库;STING数据库。(对这部分内容有感兴趣的小伙伴可以留言讨论)。
mRNA序列:mRNA序列可用于动物实验中siRNA, shRNA的设计与合成。
了解了转录翻译的具体过程以及每个过程产物最终的结构,在日常的科研活动中经常会遇到需要查找这些结构的序列用于重组载体构建或基因编辑以及基因调控等方面,那又怎么查找这些序列呢?这里我们就要用到一个功能非常强大的生物学数据库。
NCBI是美国国家生物技术信息中心(National Center for Biotechnology Information)的缩写,它是一个国际上权威的生物信息学数据库。NCBI提供了包括GenBank(DNA序列数据库)、PubMed(文献检索系统)、Nucleotide(核苷酸序列数据库)、Genome(基因组数据库)、Structure(结构数据库或称分子模型数据库)、Taxonomy(生物学门类数据库)、PopSet等在内的多个子库,涵盖了生物技术和生物医学的多个方面,是科研人员的重要资源。
网址:https://www.ncbi.nlm.nih.gov及网页截图如下:
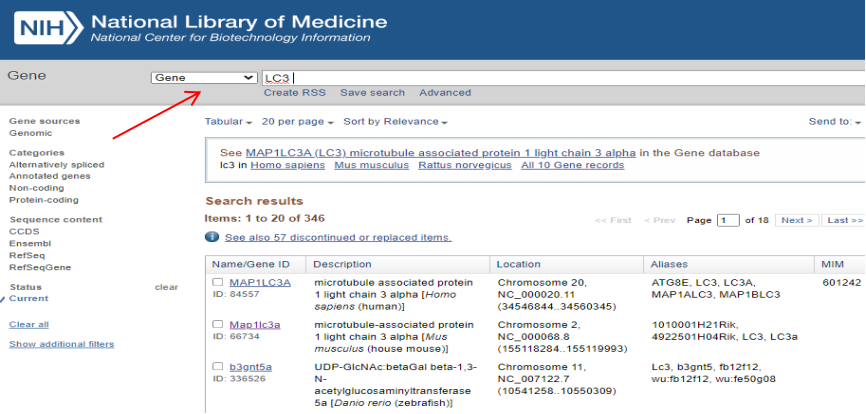
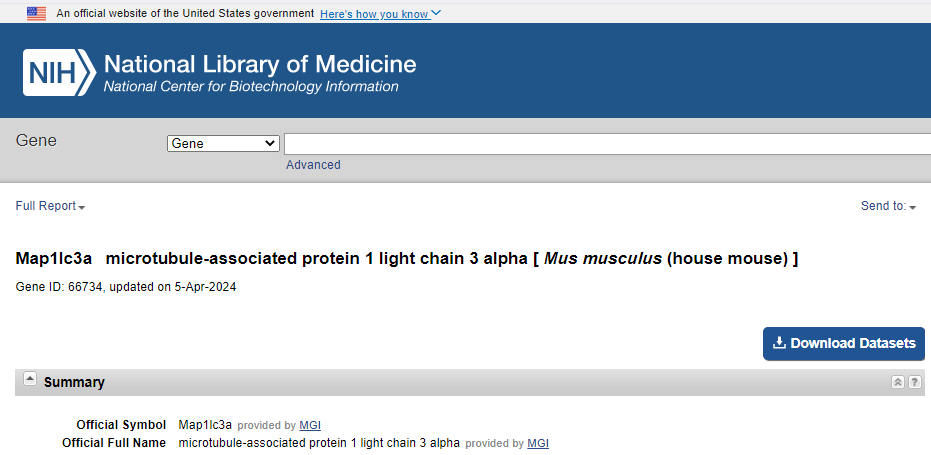
Gene序列:打开NCBI,选择Gene,输入所需要查找的基因,点击search, 点击对应的物种前的基因,找到NCBI Reference Sequence。可以看到Genomic,直接点击Genomic下面的FASTA,可下载基因序列。
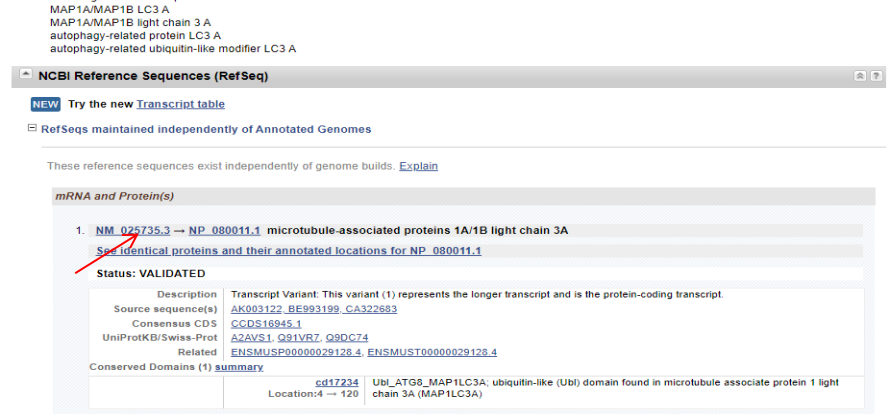
mRNA和Protein序列:点击NM开头的转录本,跳转进去就是mRNA,点击Fasta,就可以下载mRNA序列;点击NP就能得到mRNA对应的蛋白序列。
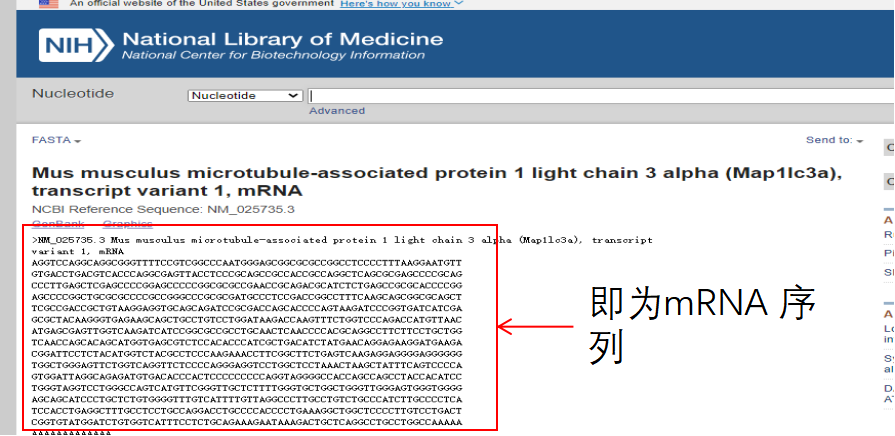
点击FASTA,即为mRNA序列:
下翻可见其CDS序列,点击CDS,CDS序列被标记,可复制CDS序列。


同理蛋白质序列可点击该页面的NP编号,点击FASTA,即可得到蛋白序列。


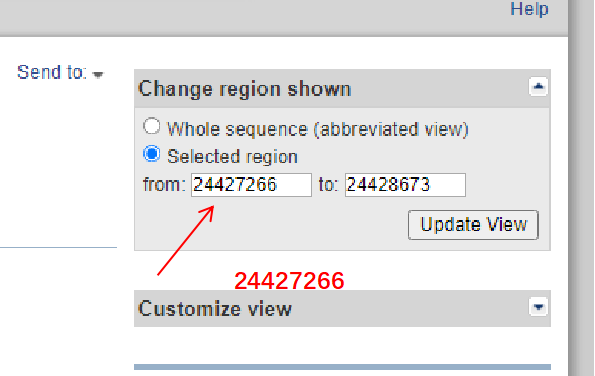
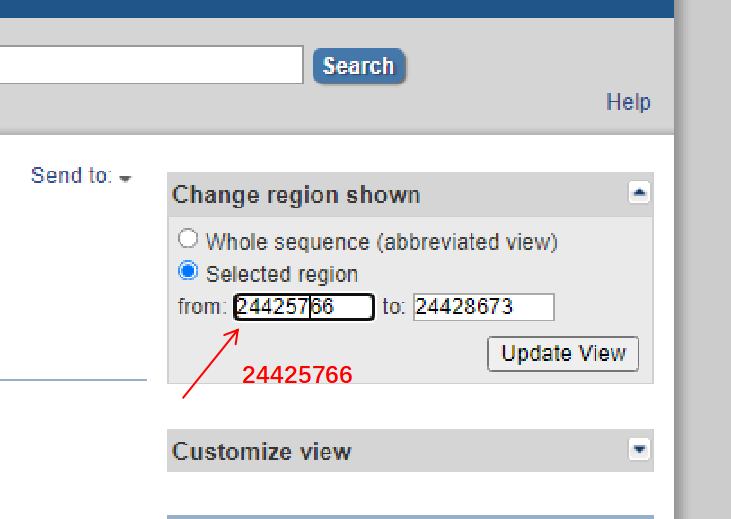
启动子序列:进入GeneBank,启动子在mRNA的前1500-2000bp左右,因此在左侧的区段设置往前1500bp,点击Update View可得,序列前1500bp即为启动子序列。
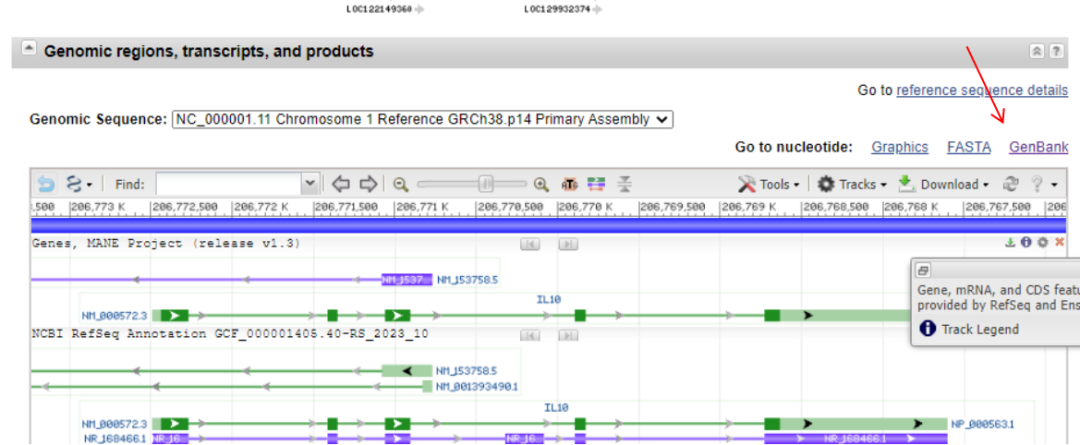

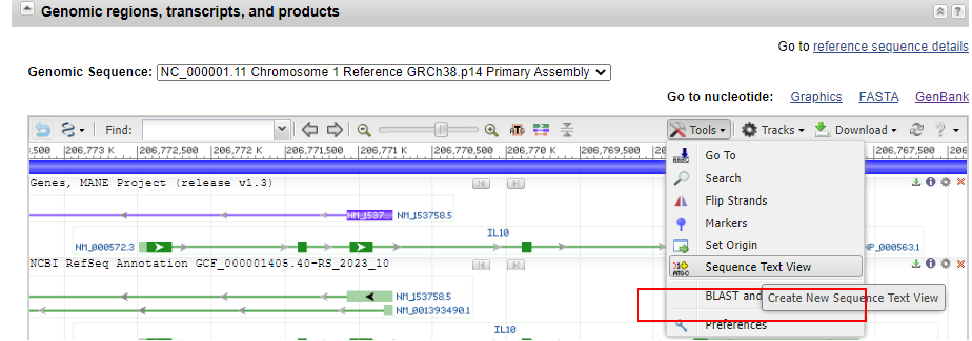
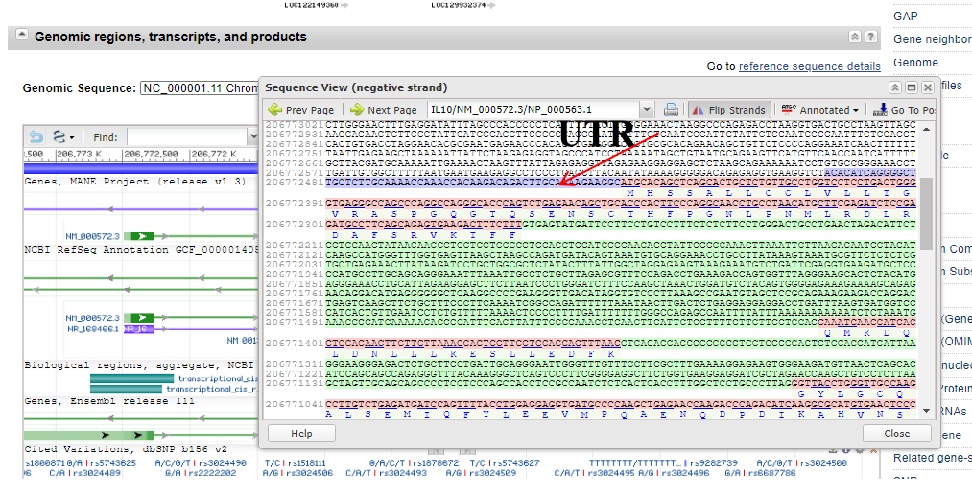
UTR序列:找到tool,序列查看,蓝色为5’UTR和3’UTR, 红色为CDS,绿色为内含子。
好了,今天的文献解读就到这里,可以推给有需要的朋友或者同学噢~


电话:400-691-6686
在线时间:8:00-24:00

微信关注公众号
















 湘公网安备
湘公网安备